Having just completed the machine learning course in Coursera, time to put the knowledge to good use. Neural networks seem to be the most promising among the classification algorithms (logistic regression and SVMs being the others covered in the course) -- I did do bit of mucking around with logistic regression, but the results were singularly disappointing.
Since we're dealing with neural networks, no need to be picky with what features to use; in addition to the ten parameters considered the last time, let's throw in as many additional ones that we can think of, and let the algorithm sort it out. Here are the features forming the input layer (the features are normalized -- something I didn't do the last time):
The examples are a total of 560 matches from the 2010-11 and 2011-12 seasons (we ignore the first few weeks of each season to a) get things to settle down and b) avoid division-by-zero errors for some of the features (e.g. when we're considering the first match a team plays in the season).
350 matches are used as the training set and 30%, i.e. 105, from the remainder form the cross validation set.
After a lot of number crunching, the results are not too good, at least not yet. It looks like I'll be needing more data (as indicated by the results from the learning curve plots). A lambda value of 0.16 or 0.32 seems to be the most promising.
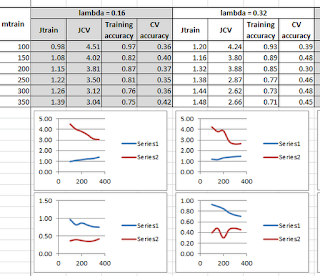
The next step is to get the results for the 2009-10 season -- and earlier if required. More grunt work. Stay tuned.
Update: Well, I went all out and got the results for three seasons -- 2007-08, 2008-09 and 2009-10 -- but no cigar; the prediction accuracy refuses to go above ~50%, whatever values of lambda and feature list I consider (I added two more features to the above list: total games played so far by both teams). It might be possible to squeeze out a bit more by running a genetic algorithm and figuring out the best lambda value and features, but I don't think the effort is worth it. Question: what is the minimal prediction accuracy required to get a 20% return on bets over the long-term, e.g., over an entire season?
Since we're dealing with neural networks, no need to be picky with what features to use; in addition to the ten parameters considered the last time, let's throw in as many additional ones that we can think of, and let the algorithm sort it out. Here are the features forming the input layer (the features are normalized -- something I didn't do the last time):
- Home record of home team
- Away record of away team
- Record of home team
- Record of away team
- Record of home team in last three games
- Record of away team in last three games
- Record of home team in last five games
- Record of away team in last five games
- Record of home team in last seven games
- Record of away team in last seven games
- Record of home team in last three home games
- Record of away team in last three away games
- Record of home team in last five home games
- Record of away team in last five away games
- Record of home team in last seven home games
- Record of away team in last seven away games
- Total goals scored by home team
- Total goals scored against home team
- Total goals scored by away team
- Total goals scored against away team
- Position of home team in points table
- Position of away team in points table
The examples are a total of 560 matches from the 2010-11 and 2011-12 seasons (we ignore the first few weeks of each season to a) get things to settle down and b) avoid division-by-zero errors for some of the features (e.g. when we're considering the first match a team plays in the season).
350 matches are used as the training set and 30%, i.e. 105, from the remainder form the cross validation set.
After a lot of number crunching, the results are not too good, at least not yet. It looks like I'll be needing more data (as indicated by the results from the learning curve plots). A lambda value of 0.16 or 0.32 seems to be the most promising.

The next step is to get the results for the 2009-10 season -- and earlier if required. More grunt work. Stay tuned.
Update: Well, I went all out and got the results for three seasons -- 2007-08, 2008-09 and 2009-10 -- but no cigar; the prediction accuracy refuses to go above ~50%, whatever values of lambda and feature list I consider (I added two more features to the above list: total games played so far by both teams). It might be possible to squeeze out a bit more by running a genetic algorithm and figuring out the best lambda value and features, but I don't think the effort is worth it. Question: what is the minimal prediction accuracy required to get a 20% return on bets over the long-term, e.g., over an entire season?
