Saturday, July 30, 2011
GitHub
I've finally gotten around to collecting all my code in a single place. This is a pretty much complete collection, except for my JSON implementation for VisualWorks. A recent scare with my home laptop (a faulty chip related to the display) is the reason for this. I have an external drive where I periodically back up stuff, but I was not able to access my files during the absence of the laptop. I could have taken them from the external drive, but didn't want the hassle of again bringing the laptop contents in sync; not to mention I didn't have much time during this period due to a family emergency.
Thursday, July 14, 2011
Predicting the English Premier League - Part 2
As promised, here are the results of the number crunching. Some of the number crunching is still ongoing as I type this -- to figure out which of the parameters give the best results (the code in the AWS instance is running for six days; hopefully it will terminate before I hit the free tier limit of 750 hours).
First, a list of the prediction methods considered:
1. Homegrown method 1: In this method, we consider three parameters: home advantage, total form and recent form (three matches). Whichever team comes out on top on the cumulative score based on these three factors is designated the winner (no draws in this method).
2. Homegrown method 2: This method uses historical (this season only) values for fractions of home wins, draws and away wins; generates a random number between 0.0 and 1.0, and chooses one option based on where the number falls in the spectrum (length of each segment in the spectrum (HW, DR, AW) determined by the historical averages).
3. Random: Generate a random number between 0.0 and 1.0. If this is <= 0.33, it's a home team win; if it's between 0.33 and 0.66, it's a draw; otherwise it's an away team win.
4. Linear (GLM): The generalized linear model with least squares regression.
5. KNN: The K Nearest Neighbours method. There are two variations to this -- one where we simply consider the three classes as home win, draw, and away win; the other where we convert the three classes to real numbers. We also vary the number of neighbours considered from one to three.
Some general notes about the exercise:
1. We use data from match-week 10 to match-week 21 (inclusive) as training data for GLM and KNN
2. Predictions are for match-week 22 onwards
3. All match-weeks do not have the same number of games for various reasons (scheduling, snow, etc.)
4. These are the predictors used:
Here are the results of the prediction, first in table format, followed by graphs (click to enlarge):


As I mentioned earlier, pretty 'meh' results. Maybe the brute force method to identify the best parameters will yield something better. This method basically considers all the combinations of parameters from the above ten, and computes the average accuracy of prediction -- for the same training data and the same prediction period -- for all of them, and picks the combination (there are actually two combinations, one for GLM and one for KNN) with the highest value. But I'm not holding my breath.
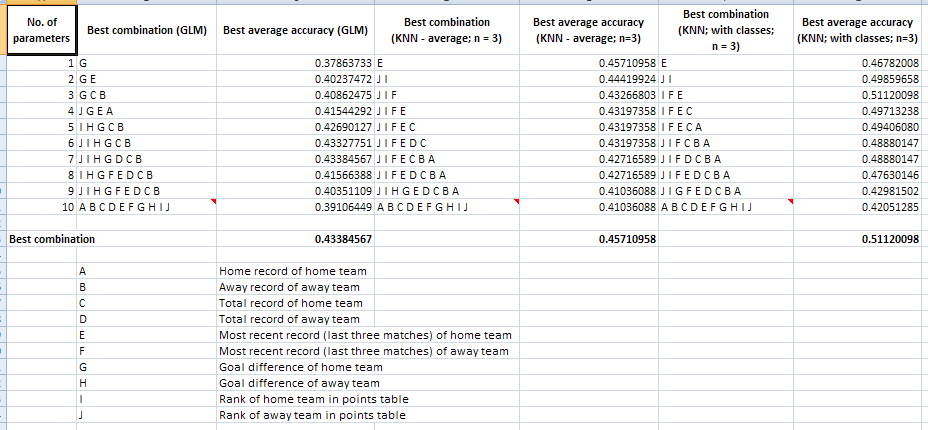
Update: The brute force number crunching is finally done and the results are in. KNN (n=3) with classes, withtwo three parameters -- the away record of the away team and the total record of the home team the most recent records of the two teams and the rank of the home team -- gives the most accurate predictions:

First, a list of the prediction methods considered:
1. Homegrown method 1: In this method, we consider three parameters: home advantage, total form and recent form (three matches). Whichever team comes out on top on the cumulative score based on these three factors is designated the winner (no draws in this method).
2. Homegrown method 2: This method uses historical (this season only) values for fractions of home wins, draws and away wins; generates a random number between 0.0 and 1.0, and chooses one option based on where the number falls in the spectrum (length of each segment in the spectrum (HW, DR, AW) determined by the historical averages).
3. Random: Generate a random number between 0.0 and 1.0. If this is <= 0.33, it's a home team win; if it's between 0.33 and 0.66, it's a draw; otherwise it's an away team win.
4. Linear (GLM): The generalized linear model with least squares regression.
5. KNN: The K Nearest Neighbours method. There are two variations to this -- one where we simply consider the three classes as home win, draw, and away win; the other where we convert the three classes to real numbers. We also vary the number of neighbours considered from one to three.
Some general notes about the exercise:
1. We use data from match-week 10 to match-week 21 (inclusive) as training data for GLM and KNN
2. Predictions are for match-week 22 onwards
3. All match-weeks do not have the same number of games for various reasons (scheduling, snow, etc.)
4. These are the predictors used:
- Home record of home team
- Away record of away team
- Total record of home team
- Total record of away team
- Most recent (three matches) record of home team
- Most recent (three matches) record of away team
- Goal difference of home team
- Goal difference of away team
- Rank in points table of home team
- Rank in points table of away team
Here are the results of the prediction, first in table format, followed by graphs (click to enlarge):


As I mentioned earlier, pretty 'meh' results. Maybe the brute force method to identify the best parameters will yield something better. This method basically considers all the combinations of parameters from the above ten, and computes the average accuracy of prediction -- for the same training data and the same prediction period -- for all of them, and picks the combination (there are actually two combinations, one for GLM and one for KNN) with the highest value. But I'm not holding my breath.
Update: The brute force number crunching is finally done and the results are in. KNN (n=3) with classes, with
Subscribe to:
Comments (Atom)
